# 选择✨
- 使用 MySQL 作为存储数据库;
- 使用 SQLAlchemy 作为数据库构造的工具;
在线工具 Freedgo (opens new window) 制作;使用 navicat 构造数据库模型WARNING
注意:如果提示连接失败,请尝试排查以下错误:
- 网络是否连接正常;
- 防火墙是否开放 3306 默认端口(或自定义);
- 数据库是否放开远程连接; 参见:记一次 Navicat for MySQL 10060 错误的解决过程 - SegmentFault 思否 (opens new window)
# 字段类型
一篇文章看懂 mysql 中 varchar 能存多少汉字、数字,以及 varchar(100)和 varchar(10)的区别 - 那些年的代码 - 博客园 (opens new window)
# 数据表
在设计数据库的时候,我们以基金、用户、基金经理作为三个数据主体进行发散。基金和用户之间通过申购、赎回行为联系起来;基金与经理之间通过管理行为联系起来;而基金自身又有每日净值,申购、赎回费率等属性。
- 我们首先根据设计绘制出 E-R 图
- 然后根据 E-R 图导出 SQL 文件
- 然后生成数据表
mysql> create database {DB_NAME}; # 创建数据库
mysql> use {DB_NAME}; # 使用已创建的数据库
mysql> set names utf8; # 设置编码
mysql> source {SQL_PATH} # 导入备份数据库
其他用到的命令:
SELECT concat('DROP TABLE IF EXISTS ', table_name, ';')
FROM information_schema.tables
WHERE table_schema = '{DB_NAME}';
- 数据库设计
最后编写 ORM 代码;当然,我们也可以使用sqlacodegen (opens new window) 为已存在的数据库生成 SQLAlchemy / Flask-SQLAlchemy 模型类 (opens new window)。
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysqlclient (a maintained fork of MySQL-Python)
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# PyMySQL
engine = create_engine('mysql+pymysql://scott:tiger@localhost/foo')
默认情况下,Flask-SQLAlchemy 会根据模型类的名称生成一个表名称,生成规则如下:
FooBar --> foo_bar # 驼峰命名改为小写下划线
Baz --> baz # 单个单词的改为小写
Some parts that are required in SQLAlchemy are optional in Flask-SQLAlchemy. For instance the table name is automatically set for you unless overridden. It’s derived from the class name converted to lowercase and with “CamelCase” converted to “camel_case”. To override the table name, set the
__tablename__class attribute.
来源见此:Declaring Models — Flask-SQLAlchemy Documentation (2.x) (opens new window)
# 声明关系对应模型
# 一对多(one-to-many)
一对多关系将一个外键sqlalchemy.schema.ForeignKey定义在引用父表的子表上。然后在父节点上指定relationship(),以引用由子节点表示的一组项:
class Parent(Base):
__tablename__ = 'parent'
id = Column(Integer, primary_key=True)
children = relationship("Child")
class Child(Base):
__tablename__ = 'child'
id = Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('parent.id'))
要建立一对多和反过来多对一的双向关系,就指定一个附加的 relationship(),并使用relationship.back_populates将两者连接起来:
class Parent(Base):
__tablename__ = 'parent'
id = Column(Integer, primary_key=True)
children = relationship("Child", back_populates="parent")
class Child(Base):
__tablename__ = 'child'
id = Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('parent.id'))
parent = relationship("Parent", back_populates="children")
这样,子就获得一个具有“多对一”的父级属性。
::: 注意
我们注意到,在relationship() 上,既可以使用relationship.backref选项,又可以使用relationship.back_populates,那么这两者之间有什么区别呢?
:::
back_populatesvsbackrefpython - When do I need to use sqlalchemy back_populates? - Stack Overflow (opens new window)
backref is more succinct because you don't need to declare the relation on both classes, but in practice I find it not worth to save this on line. I think back_populates is better, not only because in python culture "Explicit is better than implicit" (Zen of Python), but when you have many models, with a quick glance at its declaration you can see all relationships and their names instead of going over all related models. Also, a nice side benefit of back_populates is that you get auto-complete on both directions on most IDEs.
英文不好的同学可以参考本人下文翻译:
backref更为简洁,因为您不需要在两个类上都声明该关系,但是实践中,我发现这一点不值得作为准则。基于以下原因,我认为back_populates更好:
- 不仅因为在 python 文化中,“显式比隐式更好”(Python 之禅);
- 而且当我们创建了许多模型时,快速浏览一下它的声明,就可以看到所有关系及其名称,而不用去在所有相关模型上慢慢查找;
- 另外,back_populates 的一个不错的好处是,您可以在大多数 IDE 的两个方向上自动完成。(TODO:此处不知道如何实现)
# 为“一对多”关系配置删除行为
通常情况下,当所有子对象所属的父对象被删除时,子对象也应该被删除。要配置这种“皮之不存,毛将焉附?”的关系行为时,使用delete (opens new window) 中描述的 delete 级联选项。一种典型的案例是:用户注销账户时,清空其账户历史发言信息。另一种情形是,当子对象与其父对象解除关联时,子对象本身可以被删除,要实现此行为请参考delete-orphan (opens new window) 。
另请参考:Using foreign key ON DELETE cascade with ORM relationships (opens new window)
# 多对一(Many To One)
TODO:Basic Relationship Patterns — SQLAlchemy 1.4 Documentation (opens new window)
# 事务
代码:backend.fundmate.database.save()
关于SQLALCHEMY_COMMIT_ON_TEARDOWN的讨论:
- 关于 Flask-SQLAlchemy 事务提交有趣的探讨 - SegmentFault 思否 (opens new window)
- SQLAlchemy 两种不同方式 commit() 时间开支的问题 - 知乎 (opens new window)
- 关于 flask-sqlalchemy 中数据库操作的问题整理 - 简书 (opens new window)
# 声明模型¶
通常下,Flask-SQLAlchemy 的行为就像一个来自 declarative (opens new window) 扩展配置正确的 declarative 基类。因此,我们强烈建议您阅读 SQLAlchemy 文档以获取一个全面的参考。尽管如此,我们这里还是给出了最常用的示例。
需要牢记的事情:
- 您的所有模型的基类叫做 db.Model。它存储在您必须创建的 SQLAlchemy 实例上。 细节请参阅 快速入门 (opens new window)。
- 有一些部分在 SQLAlchemy 上是必选的,但是在 Flask-SQLAlchemy 上是可选的。 比如表名是自动地为您设置好的,除非您想要覆盖它。它是从转成小写的类名派生出来的,即 “CamelCase” 转换为 “camel_case”。
# 简单示例
一个非常简单的例子:
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True)
email = db.Column(db.String(120), unique=True)
def __init__(self, username, email):
self.username = username
self.email = email
def __repr__(self):
return '<User %r>' % self.username
用 Column 来定义一列。列名就是您赋值给那个变量的名称。如果您想要在表中使用不同的名称,您可以提供一个想要的列名的字符串作为可选第一个参数。主键用 primary_key=True 标记。可以把多个键标记为主键,此时它们作为复合主键。
# 一对一
DailyWorth 与 Fund
# 一对多(one-to-many)关系
最为常见的关系就是一对多的关系。因为关系在它们建立之前就已经声明,您可以使用 字符串来指代还没有创建的类(例如如果 Person 定义了一个到 Article 的关系,而 Article 在文件的后面才会声明)。
关系使用 relationship() (opens new window) 函数表示。然而外键必须用类 sqlalchemy.schema.ForeignKey (opens new window) 来单独声明:
class Person(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
addresses = db.relationship('Address', backref='person',
lazy='dynamic')
class Address(db.Model):
id = db.Column(db.Integer, primary_key=True)
email = db.Column(db.String(50))
person_id = db.Column(db.Integer, db.ForeignKey('person.id'))
db.relationship() 做了什么?这个函数返回一个可以做许多事情的新属性。在本案例中,我们让它指向 Address 类并加载多个地址。它如何知道会返回不止一个地址?因为 SQLALchemy 从您的声明中猜测了一个有用的默认值。 如果您想要一对一关系,您可以把 uselist=False 传给 relationship() (opens new window) 。
那么 backref 和 lazy 意味着什么了?backref 是一个在 Address 类上声明新属性的简单方法。您也可以使用 my_address.person 来获取使用该地址(address)的人(person)。lazy 决定了 SQLAlchemy 什么时候从数据库中加载数据:
'select'(默认值) 就是说 SQLAlchemy 会使用一个标准的 select 语句必要时一次加载数据。'joined'告诉 SQLAlchemy 使用 JOIN 语句作为父级在同一查询中来加载关系。'subquery'类似'joined',但是 SQLAlchemy 会使用子查询。'dynamic'在有多条数据的时候是特别有用的。不是直接加载这些数据,SQLAlchemy 会返回一个查询对象,在加载数据前您可以过滤(提取)它们。
您如何为反向引用(backrefs)定义惰性(lazy)状态?使用 backref() (opens new window) 函数:
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
addresses = db.relationship('Address',
backref=db.backref('person', lazy='joined'), lazy='dynamic')
# 多对多(many-to-many)关系
User 和 Role 表之间互为多对多关系,我们需要定义一个用于关系的辅助表。对于这个辅助表,强烈建议 不 使用模型,而是采用一个实际的表:
tags = db.Table('tags',
db.Column('tag_id', db.Integer, db.ForeignKey('tag.id')),
db.Column('page_id', db.Integer, db.ForeignKey('page.id'))
)
class Page(db.Model):
id = db.Column(db.Integer, primary_key=True)
tags = db.relationship('Tag', secondary=tags,
backref=db.backref('pages', lazy='dynamic'))
class Tag(db.Model):
id = db.Column(db.Integer, primary_key=True)
这里我们配置 Page.tags 加载后作为标签的列表,因为我们并不期望每页出现太多的标签。而每个 tag 的页面列表( Tag.pages)是一个动态的反向引用。 正如上面提到的,这意味着您会得到一个可以发起 select 的查询对象。 关联对象模式是多对多模式的一种变体: 当关联表包含左右表的外键之外的其他列时使用它。
class FundMgr(PkModel):
pass
funds = relationship('Fund', secondary='fund_mgr', back_populates='mgrs')
注意两个表之间secondary='',后面应该跟表名。
在 idealyard (opens new window) 项目中,我们的文章和作者就是一对多的关系。本例中,我们的用户(User)和账户(Account)也是这种关系。
TODO
此处为了简化模型,我们默认一个账户只属于一个用户,然而在实际项目中,我们可能在后期设计中引入“家庭账户”或者“共同管理账户”的设计,此时,用户和账户的关系就会变成多对多的关系。
- relationship & ForeignKey
大多数情况下, db.relationship() 都能自行找到关系中的外键, 但有时却无法决定把哪一列作为外键。
例如, 如果 User 模型中有两个或以上的列定义为 Role 模型的外键, SQLAlchemy 就不知道该使用哪列。如果无法决定外键,你就要为 db.relationship() 提供额外参数从而确定所用外键。
# 定义关系属性
关系属性在关系的出发侧定义,即一对多关系的“一”这一侧。一个作者拥有多篇文章,在 User 模型 (opens new window) 中,我们定义了一个 articles 属性来表示对应的多篇文章:
articles = db.relationship('Article')
在本项目中,我们以基金净值(DailyWorth)为例说明用法:
每个基金每天都会有一个净值,所以在净值表中,每个基金会有多个对应值。则我们很容易写出这样的代码:
# 在Fund侧
worths = db.relationship('DailyWorth')
通过backend/fundmate/database.relationship定义。用法参见backend.fundmate.database.reference_col。
此处我们参考 demo-cookiecutter-flask/models.Role (opens new window) 写为:
# 在DailyWorth侧
fund_id = reference_col('funds', column_kwargs={'comment': '基金编号'})
fund = relationship('Fund', backref='daily_worth')
INFO
The relationship.back_populates (opens new window) parameter is a newer version of a very common SQLAlchemy feature called relationship.backref (opens new window). The relationship.backref (opens new window) parameter hasn’t gone anywhere and will always remain available! The relationship.back_populates (opens new window) is the same thing, except a little more verbose and easier to manipulate. For an overview of the entire topic, see the section Linking Relationships with Backref (opens new window).
参见:Object Relational Tutorial — SQLAlchemy 1.3 Documentation (opens new window)
通过 db.relationship(),Role 模型有了一个可以获得对应角色所有用户的属性 users。默认是列表形式,lazy='dynamic'时返回的是一个 query 对象。即 relationship 提供了 Role 对 User 的访问。
而 backref 正好相反,提供了 User 对 Role 的访问。
不妨设一个 Role 实例为 user_role,一个 User 实例为 u。relationship 使 user_role.users 可以访问所有符合角色的用户,而 backref 使 u.role 可以获得用户对应的角色。
- Flask-SQLAlchemy 中的 relationship & backref_一个菜鸟的博客-CSDN 博客 (opens new window)
- 讲解一下 SQLAlchemy 中的 backref? - 知乎 (opens new window)
- python - When do I need to use sqlalchemy back_populates? - Stack Overflow (opens new window)
# 多对多关系
有一种说法 (opens new window) ,该说法的原始出处为:Declaring Models — Flask-SQLAlchemy Documentation (2.x) (opens new window) :
NOTE
如果您想要用多对多关系,您需要定义一个用于关系的辅助表。对于这个辅助表,强烈建议不要使用模型,而是采用一个实际的表。
如果关联对象之间只需要用 id 关联起来,我们可以将新类直接映射到关联表,无需使用辅助参数; 如我们有如下表:
class Left(Base):
__tablename__ = 'left'
id = Column(Integer, primary_key = True)
...
class Right(Base):
__tablename__ = 'right'
id = Column(Integer, primary_key = True)
...
则我们可以直接定义关联表如下:
association_table = Table('association', Base.metadata,
Column('left_id', Integer, ForeignKey('left.id')),
Column('right_id', Integer, ForeignKey('right.id'))
)
而关联对象(association object)模式是多对多的一种变体:当关联表包含左右表外键之外的其他数据列时,就需要使用该模式:
class Association(Base):
left_id = Column(Integer, ForeignKey('left.id'), primary_key=True)
right_id = Column(Integer, ForeignKey('right.id'), primary_key=True)
extra_data = Column(String(50))
left = relationship('Left', backref=backref('right_association'))
right = relationship('Right', backref=backref('left_association'))
综上所述:如果我们需要在关联中存储任何东西,则常规做法是创建一个关联对象来引用这些额外的信息,否则没有必要使用 ORM 层,创建一个关联表即可。
具体参阅下方链接:
- Basic Relationship Patterns — SQLAlchemy 1.4 Documentation (opens new window)
- Flask/SQLAlchemy - Difference between association model and association table for many-to-many relationship? - Stack Overflow (opens new window)
WARNING
实践中的 SQLAlchemy 的
relationship在一定程度上反而导致了整体表关联关系的极大复杂化,还有效率的极其低下。 如果你的数据库只有两个表的话,那么 relationship 随便定义随便用。如果只有几百条数据的话,那么也请随便玩。
但是,当数据库中有数十个表以上,单个关联层级就多过三个表以上层层关联,而且各个数据量以万为单位。那么,relationship会把整个人都搞垮,简直还不如手写 SQL 语句清晰好理解,并且效率也差在了秒级与毫秒级的区别上。
SQLAlchemy 只能很轻松处理 Many to Many,但是如果是常见的 Many to Many to Many,或者是 Many to Many to Many to Many,(禁止套娃)那简直就是噩梦。
用 SQLAlchemy 建立各种 ORM 类对象,不要用内置的关联,直接在查询的时候手动 SQL 语句!
经过实践(TODO:后期实验),我的建议是:
TIP
- 容易 SQL-Injection 注入的地方,用 SQLAlchemy 的 query;
- 创建 ORM 对象时候,用 SQLAlchemy;
- 多层关联的时候,不要用 SQLAlchemy;
- 查询的时候,用 SQL;
- 插入数据的时候,不要用 SQLAlchemy。(官方都说明了插入百万级的时候,和 SQL 插件是秒级的);
深究 SQLAlchemy 中的表关系 Table Relationships - SegmentFault 思否 (opens new window) 此处争议讨论参阅:项目里该不该用 ORM? - 知乎 (opens new window)
# 多态关联(Polymorphic Associations)
在记录费率问题时,我们需要对申购和赎回分别记录
原文:polymorphic associations - Possible to do a MySQL foreign key to one of two possible tables? - Stack Overflow (opens new window) 中文版:MySQL 表中的同一个字段能否同时是两个表的外键 - 简书 (opens new window)
python - Flask-SQLAlchemy polymorphic association - Stack Overflow (opens new window)
# 参考阅读
- SQLAlchemy 学习笔记(三):ORM 中的关系构建 - 於清樂 - 博客园 (opens new window)
- SQLAlchemy ORM 教程之三:Relationship - 简书 (opens new window)
- SQLAlchemy 进阶 | 飞污熊博客 (opens new window)
- 数据库创建
初始化时,我们需要定义初始化函数,参见:fundmate.commands.init_db,之后将数据库配置写入环境变量;我们可以直接以DATABASE_URL的方式给出数据库的链接,也可以使用更细粒度的控制方式,以实现每一种环境使用不同的配置方式。一种可参考的配置方式如下:
DATABASE_URL=sqlite:////tmp/dev.db
MYSQL_USER=
MYSQL_PASSWORD=
MYSQL_DB=
需要注意的是:
当继承 db.Model 基类的子类被声明创建时,根据 db.Model 基类继承的元类中设置的行为,类声明后会将表信息注册到 db.Model.metadata.tables 属性中。
create_all()方法被调用时正是通过这个属性来获取表信息。因此,当我们调用 create_all()前,需要确保模型类被声明创建。如果模型类存储在单独的模块中,不导入该模块就不会执行其中的代码,模型类便不会被创建,进而便无法注册表信息到 db.Model.metadata.tables 中,所以这时需要导入相应的模块。
# TODO
参见:数据 model 修改之后执行flask db migrate没有反应,探测不到代码修改 · Issue #231 · imoyao/fundmate (opens new window)
查阅资料:
- sqlalchemy 中用 db.create_all()无法建表? - 知乎 (opens new window)
- 使用 Flask-SQLAlchemy 调用 create_all()前是否需要导入模型类?为什么? - 知乎 (opens new window)
Your model classes inherit from db.Model, so you have to have db defined or imported before your models. Likewise, your Migrate instance needs to take db as an argument in the constructor. The Migrate instance and the models do not have any dependency between them, but it is common to have Migrate defined right after db, so to summarize, the usual order is db is defined/imported first, then your Migrate instance, and then your models. Note that if you use a linter, it may flag the models as being unused imports. This is fine, importing the models is necessary anyway, as Alembic and SQLAlchemy use introspection to find the models among all the imported symbols. If the models are not imported, then Alembic will think you have no models in your database schema, which is what happened to you.
fundmate.app.register_shell_context函数中需要注册之后调用flask init-db才能生成需要的数据表。
# 默认隔离事务导致的更新数据后查询失败
在将基金经理信息存入数据表(fund-mgr)时,遇到报错:
FlushError: Can't flush None value found in collection Mgr.funds
查阅资料:
flask-sqlalchemy 中 db.session.query 和 model.query 方式要怎么选择 - Flask - HelloFlask 论坛 (opens new window)
数据库隔离级别导致的问题,MySQL 默认隔离级别是可重复读(REPEATABLE-READ),所以同一个事务里面前后查询结果是相同的;建议您第一次查询后显式提交或回滚事务,然后进行第二次查询。
A Session object is basically an ongoing transaction of changes to a database (update, insert, delete). These operations aren't persisted to the database until they are committed (if your program aborts for some reason in mid-session transaction, any uncommitted changes within are lost).
The session object registers transaction operations with session.add(), but doesn't yet communicate them to the database until session.flush() is called.
session.flush() communicates a series of operations to the database (insert, update, delete). The database maintains them as pending operations in a transaction. The changes aren't persisted permanently to disk, or visible to other transactions until the database receives a COMMIT for the current transaction (which is what session.commit() does).
session.commit() commits (persists) those changes to the database.
flush() is always called as part of a call to commit() (1).
When you use a Session object to query the database, the query will return results both from the database and from the flushed parts of the uncommitted transaction it holds. By default, Session objects autoflush their operations, but this can be disabled.
Hopefully this example will make this clearer:
#---
s = Session()
s.add(Foo('A')) # The Foo('A') object has been added to the session.
# It has not been committed to the database yet,
# but is returned as part of a query.
print(1, s.query(Foo).all())
s.commit()
#---
s2 = Session()
s2.autoflush = False
s2.add(Foo('B'))
print(2, s2.query(Foo).all()) # The Foo('B') object is *not* returned
# as part of this query because it hasn't
# been flushed yet.
s2.flush() # Now, Foo('B') is in the same state as
# Foo('A') was above.
print(3, s2.query(Foo).all())
s2.rollback() # Foo('B') has not been committed, and rolling
# back the session's transaction removes it
# from the session.
print(4, s2.query(Foo).all())
#---
Output:
1 [<Foo('A')>]
2 [<Foo('A')>]
3 [<Foo('A')>, <Foo('B')>]
4 [<Foo('A')>]
解决方案,每一次 append 之后直接 commit。
mgr_ins = Mgr.filter_by_code(mgr_code)
mgr_ins.funds.append(fund_inst)
db.session.add(mgr_ins)
db.session.commit()
关于几种操作的区别参阅:SQLAlchemy commit(), flush(), expire(), refresh(), merge() - what's the difference? (opens new window)
数据库在初始化构建完成之后,我们就可以进行开发了。但是在实际的开发过程中,我们的设计会跟着开发不断迭代进化。这个时候我们就需要进行数据库的迁移。
- 数据库更新和降级
数据库迁移的主要目的是保留我们之前数据的记录,同时一旦发现数据库设计出现问题,可以通过降级回滚到之前的较旧版本中去。
此处我们使用 Flask-Migrate (opens new window) 扩展实现。具体使用英文不好的同学可以参考此处:Flask-migrate 基本使用方法 - sablier - 博客园 (opens new window)。
# E-R 图
使用freedgo (opens new window)生成 ER 图之后 格式化 (opens new window) ,当然我们也可以选择导入 dbdiagram.io (opens new window) 生成图片。 改成 Navicat GUI | DB Admin Tool for MySQL, PostgreSQL, MongoDB, MariaDB, SQL Server, Oracle & SQLite client (opens new window) 画图
用 Navicat 制作 ER 图及与 SQL 互相转化 | 王柏元的博客 | 博学广问,自律静思 (opens new window)
WARNING
# 修改允许远程连接
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY '{PASS_WORD}' WITH GRANT OPTION;
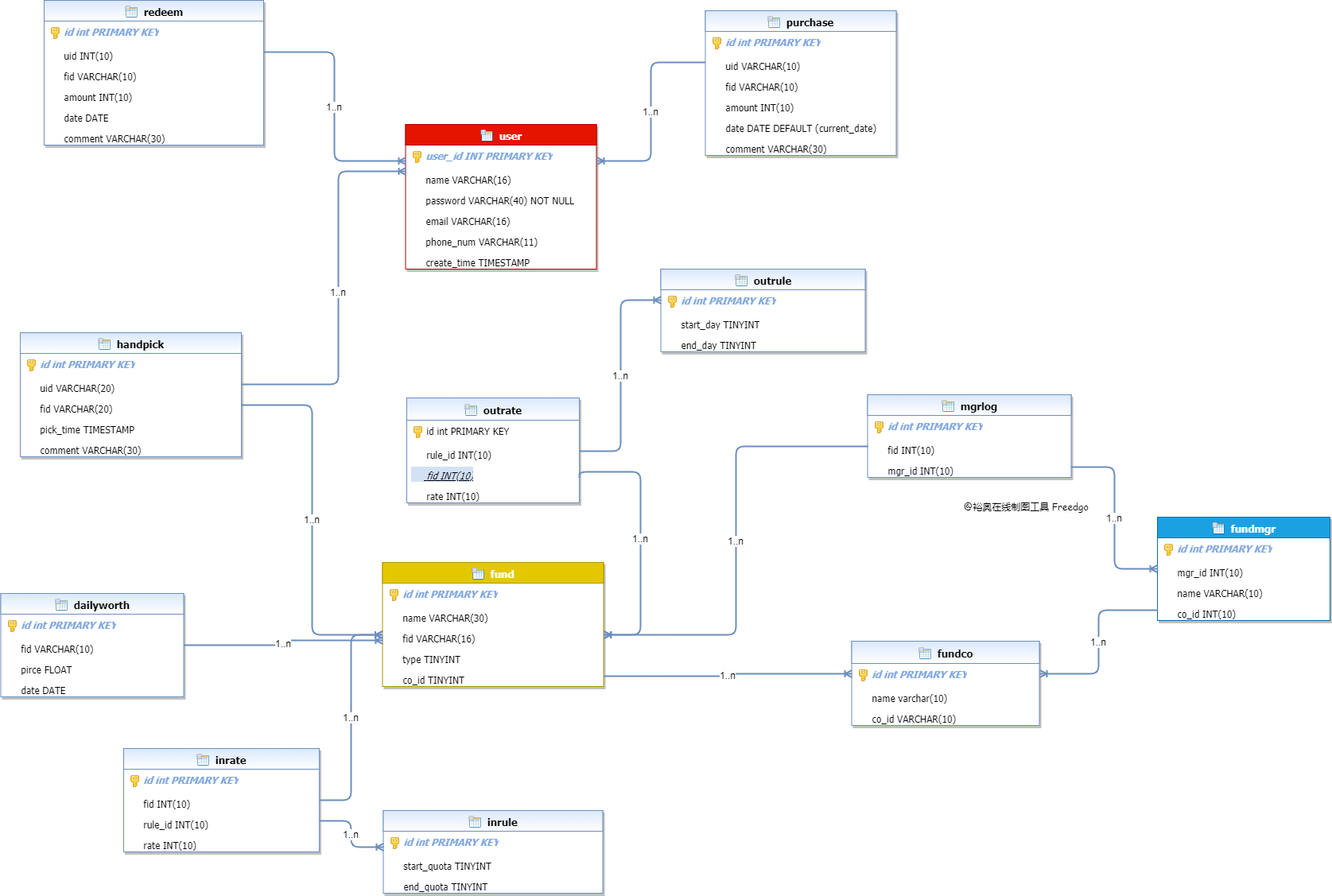
WARNING
该图示只用于数据库关系设计,具体字段定义以代码中实现为准!
在线预览参见基伴 - freedgo.com (opens new window)
# SQL 语句
SQL 文件详见 此处 (opens new window) 。
# 疑难问题
- 阶梯费率
TIP
类似于文章标签表,我们可以把收费费率看作一个标签,每一个文章(基金 ID)对应多个标签(阶梯费率),以日期的起始天数作为每一行记录去标识收费标准。
- Relationships
Relationships Between SQLAlchemy Data Models (opens new window)
- 多账本
需要一个账本表和一个用户账本关系表
参阅:我的账本_liuhong1.happy_新浪博客 (opens new window)
# 注意事项
- 连接池
- 超时释放问题 数据库连接池我们一般使用 DBUtils (opens new window) ,但是由于使用了 ORM,所以使用自带的连接池 Connection Pooling — SQLAlchemy 1.4 Documentation (opens new window) 即可。
# 遇到问题
- 增加字段长度和类型检测
No changes detected in Alembic autogeneration of migrations with Flask-SQLAlchemy - Stack Overflow (opens new window) Flask migrate does not recognise a change made in my post model. :flask (opens new window)
- 新更新内容无法探测
python - Flask-Migrate No Changes Detected to Schema on first migration - Stack Overflow (opens new window) python - flask-migrate doesn't detect models - Stack Overflow (opens new window)
filter和filter_by的区别filter_by用于使用常规kwargs对列名进行简单查询,如db.users.filter_by(name='Joe')
filter 通过使用 '==' 相等运算符也可以实现相同的效果,而不必要使用 kwargs,该运算符可以在 db.users.name 对象上重载:db.users.filter(db.users.name=='Joe')
我们还可以使用过滤器编写更强大的查询,例如以下表达式:
db.users.filter(or_(db.users.name=='Ryan', db.users.country=='England'))
源码参考:
def filter_by(**kwargs):
clauses = [
_entity_namespace_key(from_entity, key) == value
for key, value in kwargs.items()
]
return self.filter(*clauses)
python - Difference between filter and filter_by in SQLAlchemy - Stack Overflow (opens new window)
# 规范
- 数据库设计中的命名规范 - 简书 (opens new window)
- 建议收藏 - 专业的 MySQL 开发规范 (opens new window)
- 数据库设计中的命名规范 - 雪域迷城 - OSCHINA - 中文开源技术交流社区 (opens new window)